
SELECT-Anweisung
Die AQL SELECT-Anweisung wird verwendet, um Ihre Aparavi-Daten abzufragen. Die zurückgegebenen Daten sind eine Kombination der Dateien der unabhängigen Aggregatoren.
Die AQL SELECT-Anweisung wird verwendet, um Ihre Aparavi-Daten abzufragen. Die zurückgegebenen Daten sind eine Kombination der Dateien der unabhängigen Aggregatoren. Das System führt Ihre Abfrage gegen jeden Aggregator aus, sammelt die Ergebnisse und gibt dann ein kombiniertes Ergebnis zurück.
SELECT column_list
[FROM table]
[WHERE criteria]
[WHICH criteria]
[HAVING criteria]
[GROUP BY column_list]
[ORDER BY column_list]
[LIMIT count]
[OFFSET count]
SELECT
Die SELECT-Klausel definiert, welche Spalten Sie aus dem Aparavi-System abrufen möchten.
SELECT column[,column]
Um einer Spaltenüberschrift einen benutzerfreundlicheren Namen zu geben, können Sie einen AS-Alias verwenden
SELECT column AS name[,column AS name]
Um alle Spalten statt bestimmter Spalten auszuwählen, können Sie das Sternchen verwenden.
SELECT *
DISTINCT
Das Schlüsselwort DISTINCT ist ein Modifikator der SELECT-Anweisung. Bei Verwendung werden nur eindeutige Zeilen zurückgegeben.
SELECT DISTINCT column,column
Beispiel
SELECT name AS File_Name,classification AS Classification_Name
Diese Anweisung gibt zurück
- Die Aparavi-Spalten “name” und “classification”
- Die Spaltenüberschriften lauten “File_Name” und “Classification_Name”
FROM
- Anders als bei den meisten SQL-Implementierungen erfordert AQL keine
FROM-Klausel. Wenn eine AQL-Abfrage ausgeführt wird, wird dieSELECT-Anweisung gegen alle Daten unterhalb im Baum ausgeführt. Wenn Sie sie gegen den Aparavi-Root ausführen, werden alle Daten einbezogen, während bei der Ausführung gegen einen einzelnen Aggregator nur Daten innerhalb des Systems dieses Aggregators einbezogen werden. Sie können die FunktionSTOREverwenden, um die Datenquelle explizit zu definieren.
Um Daten vom aktuellen Knoten abzufragen, ist keine FROM-Klausel erforderlich.
SELECT column
Sie kann zur besseren Lesbarkeit mit der Funktion STORE ohne Parameter verwendet werden. Der folgende Code ist gleichwertig mit dem obigen.
SELECT column
FROM STORE
STORE
Die Funktion STORE wird verwendet, um zu definieren, welcher Aparavi-Knoten der übergeordnete Knoten für die einbezogenen Daten sein soll.
STORE [(Aparavi_Node)]
Die Funktion STORE nimmt einen STRING-Parameter entgegen, der definiert, welcher Knoten im Aparavi-Systembaum in den resultierenden Datensatz einbezogen werden soll. Alle Daten unterhalb dieses Knotens werden einbezogen.
SELECT column
FROM STORE('Node/Path/To/Directory')
- Verwenden Sie bei der Eingabe des Aparavi_Node-Parameters den Schrägstrich ( / ) anstelle des Backslash ( \ ).
- Die Pfadnamen sind nicht case-sensitiv -
Node/Path/To/Directoryist dasselbe wienode/path/TO/DiReCtOrY - Wenn der eingegebene Pfad ungültig ist, gibt der AQL-Parser einen Fehler aus.
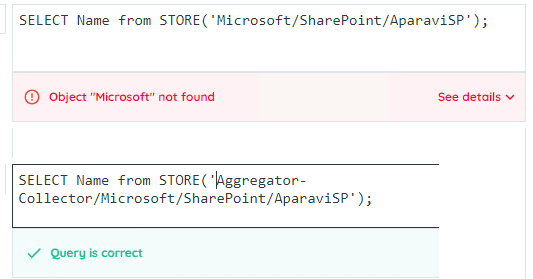
Beispiel
SELECT name AS File_Name,classification AS Classification_Name
FROM STORE('Aggregator-Collector/Microsoft/SharePoint/AparaviSP')
Diese Anweisung gibt zurück
- Die Aparavi-Spalten “name” und “classification”
- Vom Knoten AparaviSP
- Die Spaltenüberschriften lauten “File_Name” und “Classification_Name”
WHERE
Die WHERE-Klausel wird verwendet, um die zurückgegebenen Zeilen auf Zeilen zu filtern, bei denen bestimmte Bedingungen erfüllt sind.
SELECT column_name
WHERE [condition]
Mehrere Bedingungen können nach Standard-Logikkonstruktionen und Operatoren kombiniert werden.
SELECT column_name
WHERE
(column1=true AND
column2=true) OR
(column3=true)
SQL-OPERATOREN
Arithmetisch
| + | Addition | 3+2 [=5] |
|---|---|---|
| - | Subtraktion | 7-5 [=2] |
| * | Multiplikation | 2*10 [=20] |
| / | Division | 12/3 [=4] |
| % | Modulo | 5%2 [=1] |
Vergleich
| = | Gleich | 10=10 |
|---|---|---|
| > | Größer als | 10>5 |
| < | Kleiner als | 5<10 |
| >= | Größer oder gleich | 10>=10, 10>=5 |
| <= | Kleiner oder gleich | 5<=5, 5<=10 |
| <> | Ungleich | 5<>10 |
Logisch
| AND | TRUE, wenn alle durch AND getrennten Bedingungen TRUE sind | roses=red AND violets=blue |
|---|---|---|
| BETWEEN | TRUE, wenn der Operand innerhalb des Vergleichsbereichs liegt | 5 BETWEEN 1 AND 10 |
| IN | TRUE, wenn der Operand gleich einem Element einer Liste von Ausdrücken ist | red IN (red, yellow, blue) |
| LIKE | TRUE, wenn der Operand einem Muster entspricht % = 0 bis mehrere Zeichen, _ = einzelnes Zeichen | red LIKE ‘r%d’ [rd, red, road] red LIKE ‘r_d’ [red, rid] |
| NOT | Zeigt einen Datensatz an, wenn die Bedingung(en) NICHT TRUE ist/sind | NOT roses=blue |
| OR | TRUE, wenn eine der durch OR getrennten Bedingungen TRUE ist | roses=red OR roses=yellow |
| ( ) | Steuert die Reihenfolge der Operationen und AND/OR-Kombinationen | roses=red OR (roses=yellow and state=Texas) |
Beispiel
SELECT name AS File_Name,classification AS Classification_Name
FROM STORE('Aggregator-Collector/Microsoft/SharePoint/AparaviSP')
WHERE name LIKE '%project%' OR name LIKE '%.mpp' OR name LIKE '%.mpt'
Diese Anweisung gibt zurück
- Die Aparavi-Spalten “name” und “classification”
- Vom Knoten AparaviSP
- Die Spaltenüberschriften lauten “File_Name” und “Classification_Name”
- Für Microsoft Project-Dateien oder andere Dateien mit “project” im Namen
WHICH CONTAIN
WHICH CONTAIN ist eine spezielle AQL-Klausel, die die Aparavi-Wortdatenbank abfragt. Diese kombiniert die Aparavi-Dateidaten mit der Wortdatenbank, um Kontextfilter für die Daten bereitzustellen. Diese Klausel wird häufig mit den unten aufgeführten Modifikatoren ergänzt.
- Im Gegensatz zur
WHERE-Klausel arbeiten die Filter derWHICH CONTAIN-Klausel gegen den gesamten Datensatz. Stattcolumn_name=criterialautet esrecord has criteria WHICH CONTAINundWHICH CONTAINSkönnen austauschbar verwendet werden.CONTAININGkann ebenfalls auf die gleiche Weise verwendet werden, allerdings ist dasWHICH-Schlüsselwort nicht erforderlich.- Satzzeichen werden in der Wortdatenbank ignoriert.
SELECT column_name
WHICH CONTAIN word
ist dasselbe wie
SELECT column_name
WHICH CONTAINS word
ist dasselbe wie
SELECT column_name
CONTAINING word
WHICH CONTAIN 'IP'WHICH CONTAINS 'IP'CONTAINING 'IP'
NEAR
Das Schlüsselwort NEAR modifiziert die WHICH CONTAIN-Klausel. Wenn die WHICH CONTAIN-Klausel ein Wort identifiziert, erweitert NEAR die Suche um zusätzliche Wörter in der Nähe des zuerst identifizierten Wortes.
SELECT column_name
WHICH CONTAIN word AND NEAR another
Es funktioniert auch mit mehreren Werten, wenn diese in Klammern eingeschlossen und durch Kommas getrennt sind.
SELECT column_name
WHICH CONTAIN word AND NEAR (another,different,word)
WHICH CONTAIN 'IP' AND NEAR 'server'WHICH CONTAIN 'IP' AND NEAR ('server','network')
SYNONYM
Das Schlüsselwort SYNONYM modifiziert die WHICH CONTAIN-Klausel. SYNONYM sucht nach allen Wörtern, die Synonyme des Wortes sind.
AQL verwendet das Merriam-Webster-Wörterbuch zur Identifizierung von Synonymen.
SELECT column_name
WHICH CONTAIN SYNONYM (word)
WHICH CONTAIN SYNONYM ('doctor')
STEM
Das Schlüsselwort STEM modifiziert die WHICH CONTAIN-Klausel. STEM sucht nach allen Wörtern, die denselben Wortstamm wie das gegebene Wort haben.
AQL verwendet das Merriam-Webster-Wörterbuch zur Identifizierung von Wortstämmen.
SELECT column_name
WHICH CONTAIN STEM(word)
WHICH CONTAIN STEM ('drive')
PHRASE
Das Schlüsselwort PHRASE modifiziert die WHICH CONTAIN-Klausel. PHRASE sucht nach einer vollständigen Phrase statt nach einzelnen Wörtern.
SELECT column_name
WHICH CONTAIN PHRASE(phrase)
WHICH CONTAIN PHRASE ('roses are red')
OPERATOREN
| ALL | TRUE, wenn alle Auswertungen die Bedingung erfüllen |
|---|---|
| ANY | TRUE, wenn eine der Auswertungen die Bedingung erfüllt |
| NONE | TRUE, wenn keine der Auswertungen die Bedingung erfüllt |
Beispiel
SELECT name AS File_Name,classification AS Classification_Name
FROM STORE('Aggregator-Collector/Microsoft/SharePoint/AparaviSP')
WHERE name LIKE '%project%' OR name LIKE '%.mpp' OR name LIKE '%.mpt'
WHICH CONTAIN ALL SYNONYM ('start') NEAR ('date')
Diese Anweisung gibt zurück
- Die Aparavi-Spalten “name” und “classification”
- Vom Knoten AparaviSP
- Die Spaltenüberschriften lauten “File_Name” und “Classification_Name”
- Für Microsoft Project-Dateien oder andere Dateien mit “project” im Namen
- Die ein Anfangs- oder Startdatum behandeln
GROUP BY
Die GROUP BY-Klausel gruppiert Zeilen mit gleichen Werten in Zusammenfassungszeilen.
- Jede Spalte in der
SELECT-Klausel muss entweder eine AGGREGATFUNKTION sein oder in derGROUP BY-Klausel enthalten sein. - Wenn die
GROUP BY-Klausel weggelassen wird, aber AGGREGATFUNKTIONEN enthalten sind, gelten die Aggregate für die gesamte Ergebnismenge statt nur für Gruppen.
COUNT
Die Funktion COUNT gibt die Anzahl der Zeilen in der GROUP zurück.
SELECT COUNT (column_name1),column_name2
GROUP BY column_name2
Gibt den COUNT der Zeilen für jede column_name2 zurück
Wenn GROUP BY weggelassen wird
SELECT COUNT (column_name1)
Gibt den Gesamt-COUNT der Zeilen zurück
Wenn der Modifikator DISTINCT enthalten ist
SELECT DISTINCT COUNT (column_name1)
Gibt die eindeutigen column_name1-Werte über alle Zeilen zurück
SUM
Die Funktion SUM gibt die Summe einer numerischen Spalte in der GROUP zurück.
SELECT SUM (numeric_column) AS name, column_name
GROUP BY column_name
Gibt die Summe von numeric_column für jede column_name zurück
AVG
Die Funktion AVG gibt den Durchschnitt (Mittelwert) einer numerischen Spalte in der GROUP zurück.
SELECT AVG (numeric_column) AS name, column_name
GROUP BY column_name
Gibt den Mittelwert von numeric_column für jede column_name zurück
MIN
Die Funktion MIN gibt den Minimalwert einer Spalte in der GROUP zurück.
SELECT MIN (numeric_column) AS name, column_name
GROUP BY column_name
Gibt das Minimum von numeric_column für jede column_name zurück
MAX
Die Funktion MAX gibt das Maximum einer Spalte in der GROUP zurück.
SELECT MAX (column_name1) AS name
Gibt das Maximum von column_name1 zurück
Beispiel
SELECT COUNT(classification) as Classification_Count,classification AS Classification_Name
FROM STORE('Aggregator-Collector/Microsoft/SharePoint/AparaviSP')
WHERE name LIKE '%project%' OR name LIKE '%.mpp' OR name LIKE '%.mpt'
WHICH CONTAIN ALL SYNONYM ('start') NEAR ('date')
GROUP BY classification
Diese Anweisung gibt zurück
- Die Aparavi-Spalte “classification”
- Und die Anzahl der Datensätze pro “classification”
- Vom Knoten AparaviSP
- Die Spaltenüberschriften lauten “Classification_Count” und “Classification_Name”
- Für Microsoft Project-Dateien oder andere Dateien mit “project” im Namen
- Die ein Anfangs- oder Startdatum behandeln
HAVING
Die HAVING-Klausel wird verwendet, um die zurückgegebenen Zusammenfassungen auf Zusammenfassungen zu filtern, bei denen bestimmte Bedingungen erfüllt sind. Im Gegensatz zur WHERE-Klausel, die Detailzeilen betrachtet, betrachtet HAVING nur die Spalten vom Typ AGGREGATFUNKTION. Sie basiert auf dem ALIAS der Spalte.
SELECT AGG_FUNCTION(column_name1) AS alias,column_name2
GROUP BY column_name2
HAVING alias>35
Beispiel
SELECT COUNT(classification) as Classification_Count,classification AS Classification_Name
FROM STORE('Aggregator-Collector/Microsoft/SharePoint/AparaviSP')
WHERE name LIKE '%project%' OR name LIKE '%.mpp' OR name LIKE '%.mpt'
WHICH CONTAIN ALL SYNONYM ('start') NEAR ('date')
GROUP BY classification
HAVING Classification_Count>=100
Diese Anweisung gibt zurück
- Die Aparavi-Spalte “classification”
- Und die Anzahl der Datensätze pro “classification”
- Vom Knoten AparaviSP
- Die Spaltenüberschriften lauten “Classification_Count” und “Classification_Name”
- Für Microsoft Project-Dateien oder andere Dateien mit “project” im Namen
- Die ein Anfangs- oder Startdatum behandeln
- Und die Anzahl jeder “classification” beträgt mindestens 100
ORDER BY
Die ORDER BY-Klausel wird verwendet, um die Ergebnisse in aufsteigender (ASC) oder absteigender (DESC) Reihenfolge zu sortieren. Dies ist in der Regel eine Darstellungspräferenz und ändert nicht die Ergebnismenge selbst.
- Wenn nicht angegeben, wird aufsteigend (
ASC) angenommen.
SELECT column[,column]
ORDER BY column[order_direction]
Beispiel
SELECT COUNT(classification) as Classification_Count,classification AS Classification_Name
FROM STORE('Aggregator-Collector/Microsoft/SharePoint/AparaviSP')
WHERE name LIKE '%project%' OR name LIKE '%.mpp' OR name LIKE '%.mpt'
WHICH CONTAIN ALL SYNONYM ('start') NEAR ('date')
GROUP BY classification
HAVING COUNT(classification)>=100
ORDER BY COUNT(classification) DESC
Diese Anweisung gibt zurück
- Die Aparavi-Spalte “classification”
- Und die Anzahl der Datensätze pro “classification”
- Vom Knoten AparaviSP
- Die Spaltenüberschriften lauten “Classification_Count” und “Classification_Name”
- Für Microsoft Project-Dateien oder andere Dateien mit “project” im Namen
- Die ein Anfangs- oder Startdatum behandeln
- Und die Anzahl jeder “classification” beträgt mindestens 100
- Die gesamte Ergebnismenge wird nach der Anzahl jeder “classification” in absteigender Reihenfolge sortiert
LIMIT
Die LIMIT-Klausel wird verwendet, um die maximale Anzahl der zurückzugebenden Datensätze anzugeben.
- Bei Verwendung mit
ORDER BYwird die Sortierreihenfolge zuerst angewendet.
SELECT column[,column]
LIMIT [row_count]
oder mit der ORDER BY-Klausel
SELECT column[,column]
ORDER BY column[order_direction]
LIMIT [row_count]
Beispiel
SELECT COUNT(classification) as Classification_Count,classification AS Classification_Name
FROM STORE('Aggregator-Collector/Microsoft/SharePoint/AparaviSP')
WHERE name LIKE '%project%' OR name LIKE '%.mpp' OR name LIKE '%.mpt'
WHICH CONTAIN ALL SYNONYM ('start') NEAR ('date')
GROUP BY classification
HAVING COUNT(classification)>=100
ORDER BY COUNT(classification) DESC
LIMIT 500
Diese Anweisung gibt zurück
- Die Aparavi-Spalte “classification”
- Und die Anzahl der Datensätze pro “classification”
- Vom Knoten AparaviSP
- Die Spaltenüberschriften lauten “Classification_Count” und “Classification_Name”
- Für Microsoft Project-Dateien oder andere Dateien mit “project” im Namen
- Die ein Anfangs- oder Startdatum behandeln
- Und die Anzahl jeder “classification” beträgt mindestens 100
- Die gesamte Ergebnismenge wird nach der Anzahl jeder “classification” in absteigender Reihenfolge sortiert
- Die sortierte Menge gibt dann nur die ersten 500 Datensätze zurück
OFFSET
Die OFFSET-Klausel wird verwendet, um die Rückgabe der Datensätze erst nach einer bestimmten Anzahl von Datensätzen zu beginnen. Dies ermöglicht es, einen mittleren Block von Datensätzen abzurufen.
- Bei Verwendung mit
ORDER BYwird die Sortierreihenfolge zuerst angewendet.
SELECT column[,column]
OFFSET [row_count]
oder mit der ORDER BY-Klausel
SELECT column[,column]
ORDER BY column[order_direction]
OFFSET [row_count]
Beispiel
SELECT COUNT(classification) as Classification_Count,classification AS Classification_Name
FROM STORE('Aggregator-Collector/Microsoft/SharePoint/AparaviSP')
WHERE name LIKE '%project%' OR name LIKE '%.mpp' OR name LIKE '%.mpt'
WHICH CONTAIN ALL SYNONYM ('start') NEAR ('date')
GROUP BY classification
HAVING COUNT(classification)>=100
ORDER BY COUNT(classification) DESC
LIMIT 500
OFFSET 500
Diese Anweisung gibt zurück
- Die Aparavi-Spalte “classification”
- Und die Anzahl der Datensätze pro “classification”
- Vom Knoten AparaviSP
- Die Spaltenüberschriften lauten “Classification_Count” und “Classification_Name”
- Für Microsoft Project-Dateien oder andere Dateien mit “project” im Namen
- Die ein Anfangs- oder Startdatum behandeln
- Und die Anzahl jeder “classification” beträgt mindestens 100
- Die gesamte Ergebnismenge wird nach der Anzahl jeder “classification” in absteigender Reihenfolge sortiert
- Die sortierte Menge gibt dann 500 Datensätze zurück
- Beginnend ab Datensatz 501 (d.h. Datensatz 501 bis 1000)